特許の概要:特許第5768136 Patent No.:US 9,547,700 B2
■ フォワードネットワーク構造1つ以上の言葉と関連付けられるノードと、ノード同士をネットワーク状に関連付けた(リンク)構造をフォワードネットワーク構造とします。1つ以上のノードを含む層を多層構造とし、さらにレイヤの概念を導入したものです。ノードの関連付けは異なるレイヤに属するノード同士を上位層から下位層に向かって行います。これにより、計算処理速度の大幅な向上とループの回避を行えます。
■ 検索手段
検索においては1つ以上の検索キーワードでノードの言葉との合致状態からノードにポイントを設定します。
最上位層のノードから最下位層まで各層ごとに関連付けを辿ってポイントの計算を行います。
■ 検索結果の出力
最下位層でのノードのポイントのうち最大のポイントをもつノードが最も回答としての確率が高いとします。
最下位層のノードを指定し、最上位層までの関連する経路を出力します。
計算モデル、問題とアルゴリズム
■ 計算モデルフォワードネットワーク構造はグラフ理論の有向非循環グラフ(Directed acyclic graph, DAG)を基本的な計算モデルとし、レイヤの概念を導入したものです。
■ 問題
解こうとする問題は、有向非循環グラフで、複数の始点(スタートノード:入力されたキーワードを含む)と複数の終点(エンドノード)が有る時、入力された複数のキーワードを最も多く辿るパスで連結され、且つ関連するパスのうちで最も多くの合流点を含む始点と終点の対を探すことに在ります。
|
例)右図の有向グラフにおいてBとDを始点(入力されたキーワードを含む)としCとJとGを終点とする時、入力された複数のキーワードを最も多く辿るパスに繋がる始点と終点の組み合わせはどれか?また、それらの点の組み合わせの内、最も多くの合流点を結ぶパスはどれか? これらの条件を満たす始点はD、終点はJとなります。パスはJ→M→K→(I,H)→Dとなります。次の組み合わせの候補はB,D(同じ確率)とGになります。パスはG→F→E→A→(B,D)となります。 |
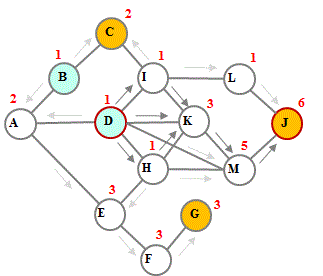
|
|
このDAGにレイヤの概念を取り入れてトポロジカルソートをかけ右図のような形にします。 この形にすることで問題を高速に処理するアルゴリズムを実現でき、大規模なグラフにも対応することができます。アルゴリズムは分割して計算することが可能で、並行して処理することができます。 |
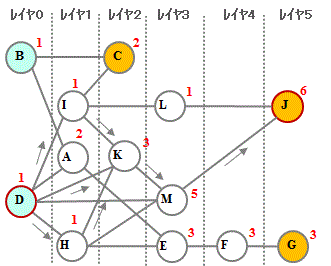
|
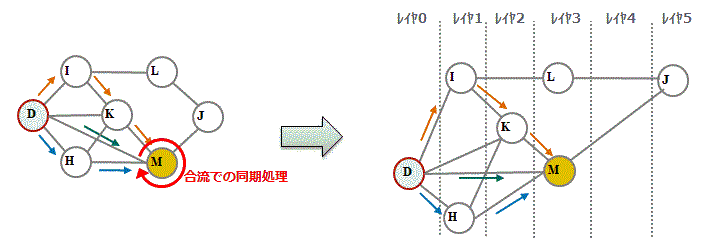
|
複数のカテゴリ、ツリーに跨って同時に検索をすることができます。例えば、医療の関連など専門分野に分かれている場合、現れた症状がいくつもの分野の病気に関連していることがあります。 このように専門分野ごとのデータベースを同時に関連付けながらすべての可能性を同時に推論する事ができます。
できること
この問題は、例えば次のような例に応用することができます。■ 因果関係を検索する
エッジ(リンク)で結ばれるノードとノードの関係が現象と原因であるようなグラフの場合、複数の現象を始点として、最も多く合流している終点を探すことで、最も関連の多い現象と原因の対を見出すことができます。これは各種の診断に応用することができます。また、「風が吹けば」、「桶屋が儲かる」、といった原因と結果のように逆の関連であっても応用できます。
■ 知識データベース
その分野での複数の優れた専門家の知識をデータベース化することで、誰でも同質の推論をすることができます。特にプラントの事故時や医療の症例検索など即応性が必要とされる状況での判断において、対応策を瞬時に推論することができます。
■ トラブルサポート
プラントや航空機などのセンサーとインターフェースを取ることで自動的にシステムの状況を推論し、次に取るべき手段を提示することができます。
■ 関連、影響範囲の検索。企業間の取引を検索する
グラフに企業間の仕入先、取引先の関連を適用した場合は広範囲での企業間の取引関連を検索することができ、ある企業の事故などによる他企業への影響範囲を調べることができます。また、複数の企業のハブとなっている企業を見出すこともできます。
■ サプライチェーン(流通、集荷)
グラフは一種のフローネットワークでもありますので、応用として次のような問題にも対応することができます。
複数の車庫と複数の倉庫と複数の店舗があり倉庫には複数の商品が複数個ある場合、検索条件として複数の商品名を指定する時、最も多くの指定された商品を輸送することのできる車庫と店舗の組み合わせとそのルートを調べることができます。
検索から推論
■情報から知識、検索から推論点としての情報(データ)を論理的に連携(リンク)することで、既知の事象から論理的に繋がる結果に「なぜ」至ったかを知ることができなければ知識であるとは言えません。そうでなければ、もしその「答え」を「否定する事実」が発見された場合、「どこが間違っていたのか」を素早く検査することができません。また、一般的な事象においては問題が複雑になればなるほど「問い」に対する「答え」が複数存在するケースが増え、経緯の評価を同時に行わなければ「より正しい答え」を得ることができません。さらには、予想と異なる事実が提示された場合、なぜなのか?ということを推論し、欠けていた事実関係を学習できることが必要です。
■膨大な情報を論理的にたどる検索
ビッグデータから得られる膨大なリンクは人の力だけでたどることは困難です。人が情報をたどって行く手順をシミュレートし積み重ねることで膨大なリンクをたどることが出来るシステムが必要です。
■「風吹けば桶屋が儲かる」「総論賛成、各論反対」
「情報」とそれらの「関連」の大規模・分散型ネットワーク構造のリンクを高速で正確に辿ることができる推論エンジンです。 出力する結果は、複数の回答とその設問(キーワード)合致率と回答に至るルート(推論パス)です。例えば「風が吹く」をキーワードとして入力すると、「桶屋が儲かる」が結果として出力され、同時に「風が吹く」から「桶屋が儲かる」に至った推論パスが出力されます。つまり、「なぜ」、「どうして」その「答え」に至ったか?も同時に得ることができます。
もうひとつの特徴は「総論賛成、各論反対」が判ることです。 色々と「情報」(意見)は分かれるが、結果としては同じ「結果」(結論)に至る過程を浮彫にすることができます。つまり「各論反対」がどこで起きたかを知ることができます。
自己学習
■ノード、エッジの自己学習文書の構文解析、音声会話のテキスト化、ツイッターの会話などから、例えば現象に対しての原因の情報が得られた場合、現象で既存のデータベースのノードを検索し、リンク(エッジ)を介して既知の原因が記録されていなかった時には未知の情報として新たなリンクとノード(原因)を記録することで学習することができます。
■リバース検索による、ミッシングリンク(エッジ)を探す
得られた回答が期待と違っていた場合に、修正のアイデアを提示できる仕組みが次のステップであり、リバース推論を用いることにより自動学習の可能性が高まります。言い換えると、「ミッシング・リンク」を見つける仕組みです。基本的には、得られるべき結果を指定することで、逆に下位層から上位層に向かって論理的に最も関連性の高いルートを選択し、得られた(間違っていると判断された)結果がたどるルートとの論理的な関連性のある最接近点を探すことになります。未知の論理的な関連性(未リンク)は、人間が判断することもありますし、あるいは過去の文献を自動的に探して発見することもできるでしょう。

製品開発: インフォセステクノロジー株式会社